The generative approach to classification (PGM), works by:
- Estimate the class-conditional probabilities, - which can be used to generate new data points, hence the name ‘generative model’
- Calculate the posterior probability using Bayes Theorem:
Key Steps
To solve for the posterior probabilities via PGM, we follow the key steps:
- Expand the posterior using logistic/softmax functions
- Determine form of arguments to the softmax function (with model assumptions)
- Estimate parameters for the resulting form
Expanding the Posterior
Two Class Case
Let us consider the key steps for the simple case of two classes.
We know the equation for joint probability to be:
We also know the sum rule (marginalisation):
And the product rule
With this, we can expand the posterior:
NOTE: the lecturer mentioned this being in the A1 likely!
Let’s have a closer look at the implications of the definition of :
Some background, the odds of an event is defined as:
We can use this to say the prior odds (odds without an observation) for class is:
Similarly, the posterior odds (odds given an observation) is:
Look familiar? This means that is the log-posterior odds of
Therefore, the posterior probability is the logistic function (sigmoid) evaluated at the log-posterior odds of
What does this mean?!
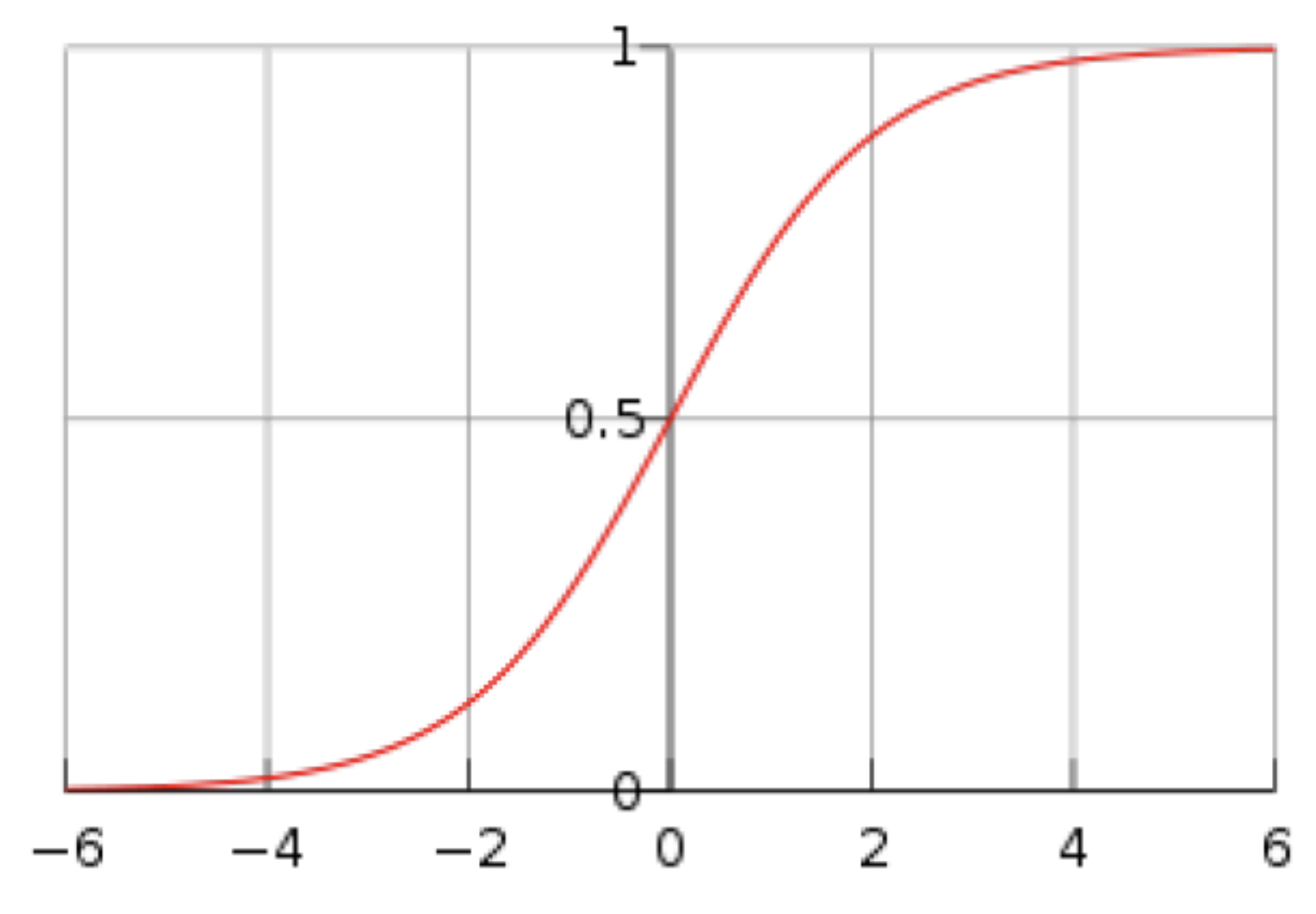
The logistic sigmoid function (as above), takes the log-posterior odds and maps it to a value between 0 and 1, thereby assigning a posterior probability to
belongs to class if , otherwise
k-Class Case
We can expand the two class case above to a general -class case:
This is the basis of the Softmax Function
Notice that the function is not the log-posterior odds as before
Also note, the total posterior probability must add to 1
What’s next?
PGM requires two more things:
- Prior class probabilities
- Class conditional densities which we’ll assume is Gaussian in this course (
GaussianNBinscikit-learn)
Gaussian Class-Conditional PDFs
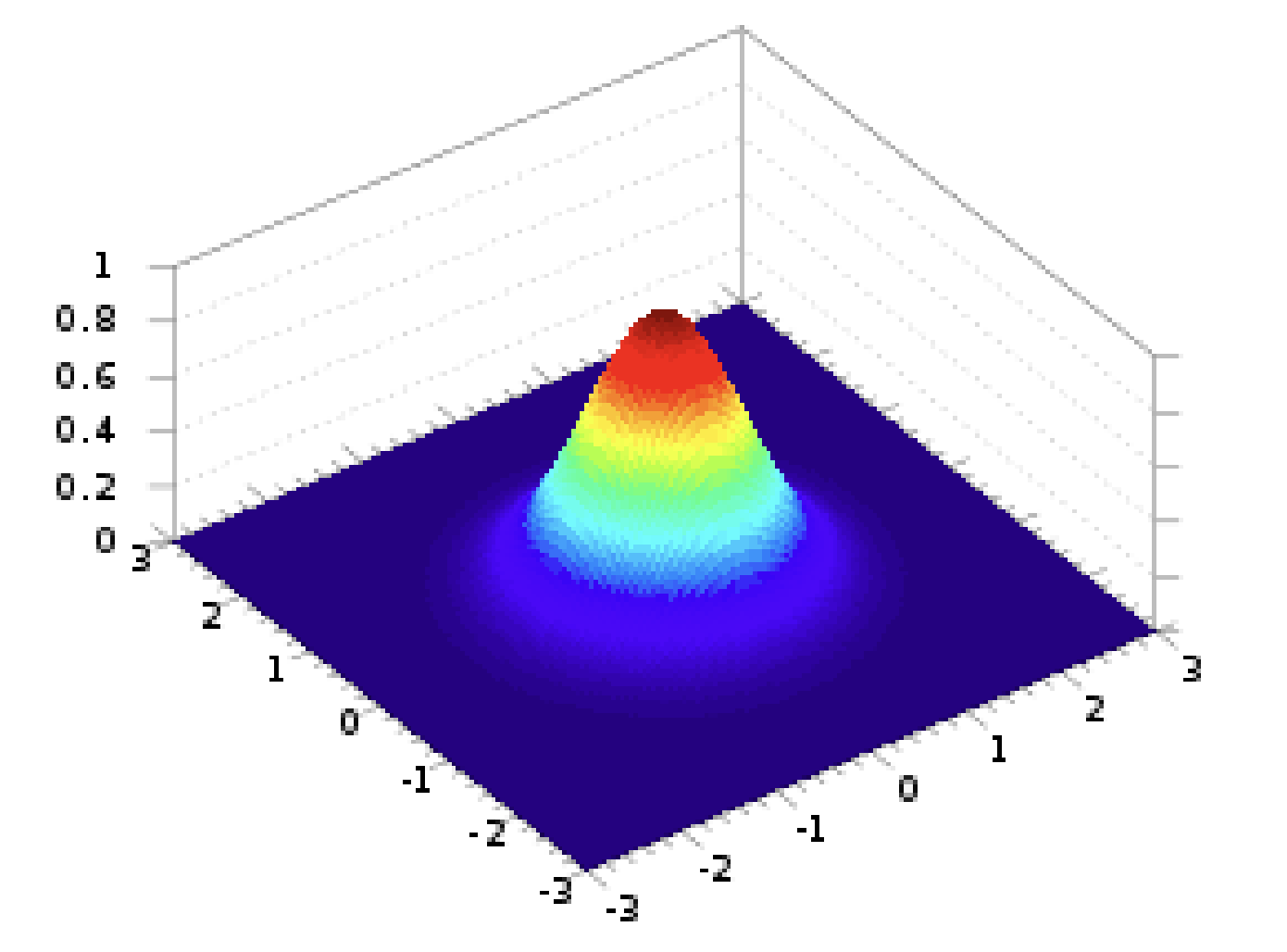
Let’s break this down:
- is a determinant
- is the mean vector for each class
- is the class covariance matrix
We’re going to assume that the class covariance matrices are the same across all classes
What’s our Log-Posterior Odds?
Two Class Case
Since we now know the class conditional PDFs, we can calculate the log-posterior odds for the two class case as we did before, assuming shared :
Wow! If we make shared, the quadratic terms () cancels out, resulting in a linear classifier. Let’s define some terms to make it more obvious:
-
- _we can do _since the covariance matrix is symmetrical _
-
- Which is the bias term (constant) and contains the prior probabilities
Making the log-posterior probability simplified to:
With the shared , we have a diagonal matrix, therefore containing parameters. Each also contains parameters. Therefore, the total amount of parameters required for the two class generative classifier is:
Where’s the decision boundary?
Where the probability of both classes are the same, i.e. they equal 0.5.
k-Class Case
Similar to above, we can find:
Parameter Estimation
To find the parameters for the class conditional densities and the prior probabilities we need a fully observed dataset, this means observations along with their class labels.
Maximum Likelihood Estimation (MLE)
We can determine the means and covariance matrix for each class using the usual methods:
Means:
With being the amount of observations in class
Covariances:
From maximum likelihood, we can find the prior probabilities as:
The Flaws of MLE
The MLE approach is expensive to compute. With input dimensions and classes:
- each class has a mean with parameters
- each class has a symmetrical covariance matrix containing parameters
This results in a parameter count of
If we share the covariance matrix, this reduces to:
However, sharing a covariance matrix may cause issues, since classes may not have the same covariances and thereby a shared matrix might not give a good description of each class.
This leads us to the Naive Bayes approach, which assumes a diagonal covariance matrix for each class, resulting in a parameter count of
This strikes a good middle ground between a per class full covariance matrix and a shared covariance matrix.
Read more in the Naive Bayes notes.