A linear Dimensionality Reduction technique for classification
It’s like PCA but focusses on separability among known categories ()
Data
- Data is a set of input-output pairs
- Inputs are real-valued -dimensional vectors
- Outputs indicate class membership of , and are positive integers from 1 to (the amount of classes)
- Inputs are collected into matrix and outputs into -dimensional vector
Binary (Two Class) Classification Example
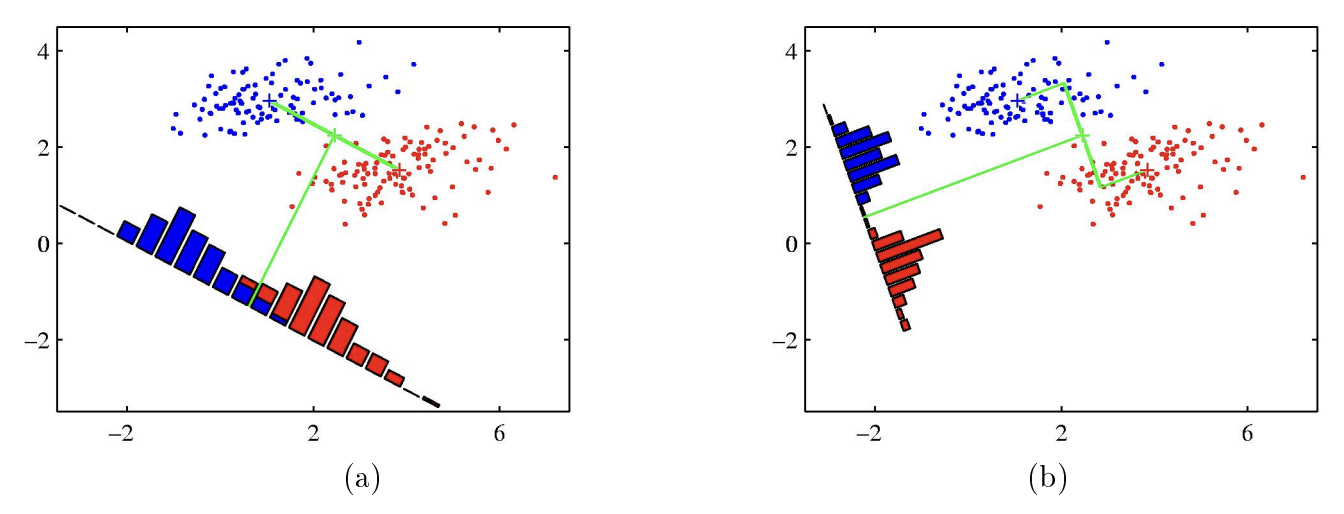
While a has greater variance, b has better separation between classes as there is less overlap between classes, making it ideal for classification problems.
Projection
LDA attempts to maximise the distance between the class means, while minimising variation (referred to as scatter in LDA) within each category.
Given a -dimensional observation , we can project it down to a single dimension as before with:
Therefore, our aim is to find as to maximise between class separation in the projected 1-d space. However, we need to decide how to quantify this, as we will in the following sections.
Means
Have be the mean of the input data as before in PCA
We define the class mean as
With:
- meaning sample indexes belonging to class
- being the total samples in class

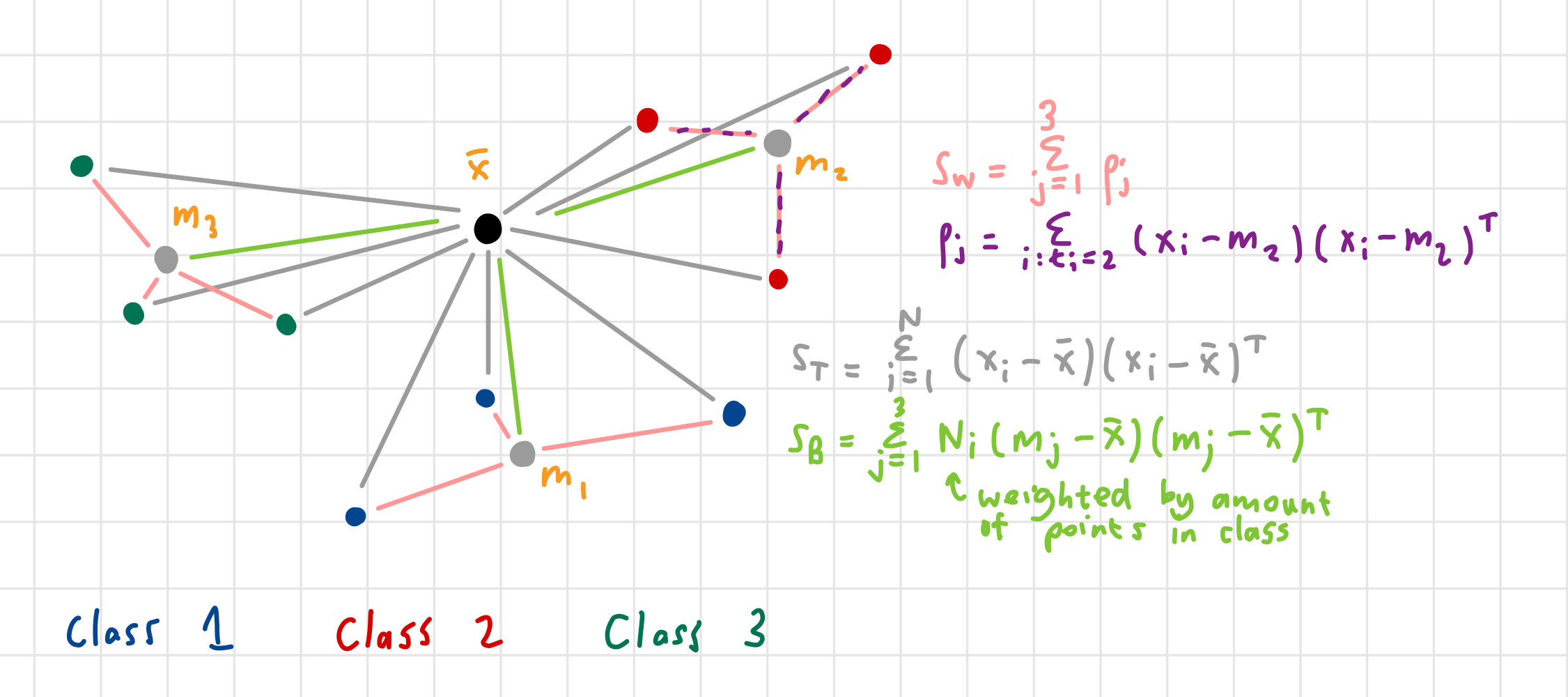
Scatter
- is the total scatter about the mean
- is the within class scatter
- is the within-class scatter for the data
- (where is the class mean of the class to which sample belongs) is the between-class scatter.
Notice that
Note: that scatter matrixes are unnormalised covariance matrices
Specifying the LDA axes
We want to find suitable axes collected into a matrix so that we can transform our -dimensional input :
The scatters of data transformed this way, can be calculated:
is the new data mean
is the new total scatter.
Likewise, we can show that the new between class scatter is and the within class scatter is .
LDA aims to have points within the same class tightly clustered, while having clusters clearly separated
One objective for finding is to optimise
However, this is not clearly defined as the quotient of matrices does not exist. The maximisation of between class scatter (separation of clusters) and minimisation of within class scatter (tightly clustered classes) are in conflict and a tradeoff is to be made
As with PCA, we find the first axis vector
Notice, as increases without bound, the function will also grow boundlessly, therefore we add the constraint that it is unit vector:
This yields the constrained optimisation problem
Hey! Its a Lagrange Multipliers problem! Let’s solve it:
The Lagrangian is:
Which can be solved
This is not quite a eigenvalue problem since is in the way, but if we assume is invertible:
it becomes an eigenvalue problem for , with solutions for being the eigenvectors corresponding to the largest eigenvalues!
How about if is not invertible?!
is not invertible if it isn’t full rank (has some zero eigenvalues).
We can find a solution in two steps:
- use PCA on to remove empty dimensions, making the transformed data invertible
- Scale the axes so that orthogonal transformations do not change within class scatter (i.e. whiten the class centered data)
- Whitening:
After whitening we have a new objective