Up until now, we’ve only considered the likelihood of a model being responsible for a single observation
Hidden Markov Models provide a way to model a sequence of observations. The feature vector at any given time is for with being the length of the sequence. The sequence is represented as
Let’s look at an example of numerical recognition from speech:
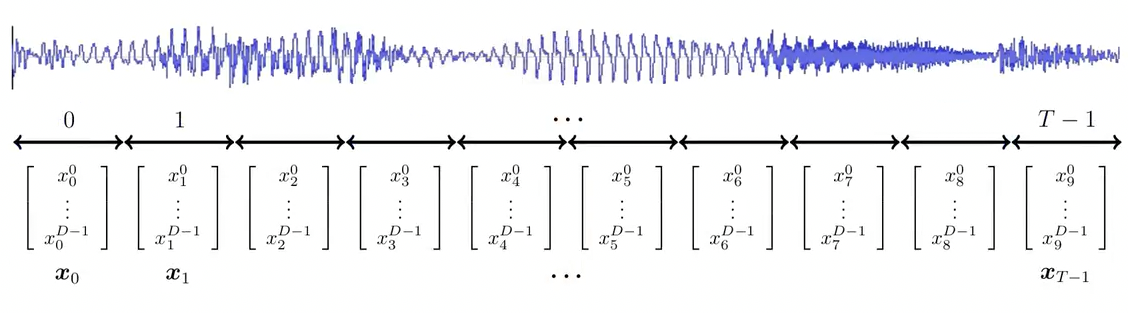 Here’s a waveform of someone saying the number “ten”.
Here’s a waveform of someone saying the number “ten”.
The waveform is split into short (say 20ms) chunks and converted into feature vectors using preprocessing techniques.
We’ll notice that the word will not be spoken at the exact same rate each time and therefore the sequence length may be varied
Modelling this with a three component GMM, the model wont be able to distinguish “net” from “ten” since it does not consider order.
So instead, let’s model each sound separately:

The model has a fixed amount of states which is typically much less than the amount of samples passed through.
Let’s go back to a more general case:
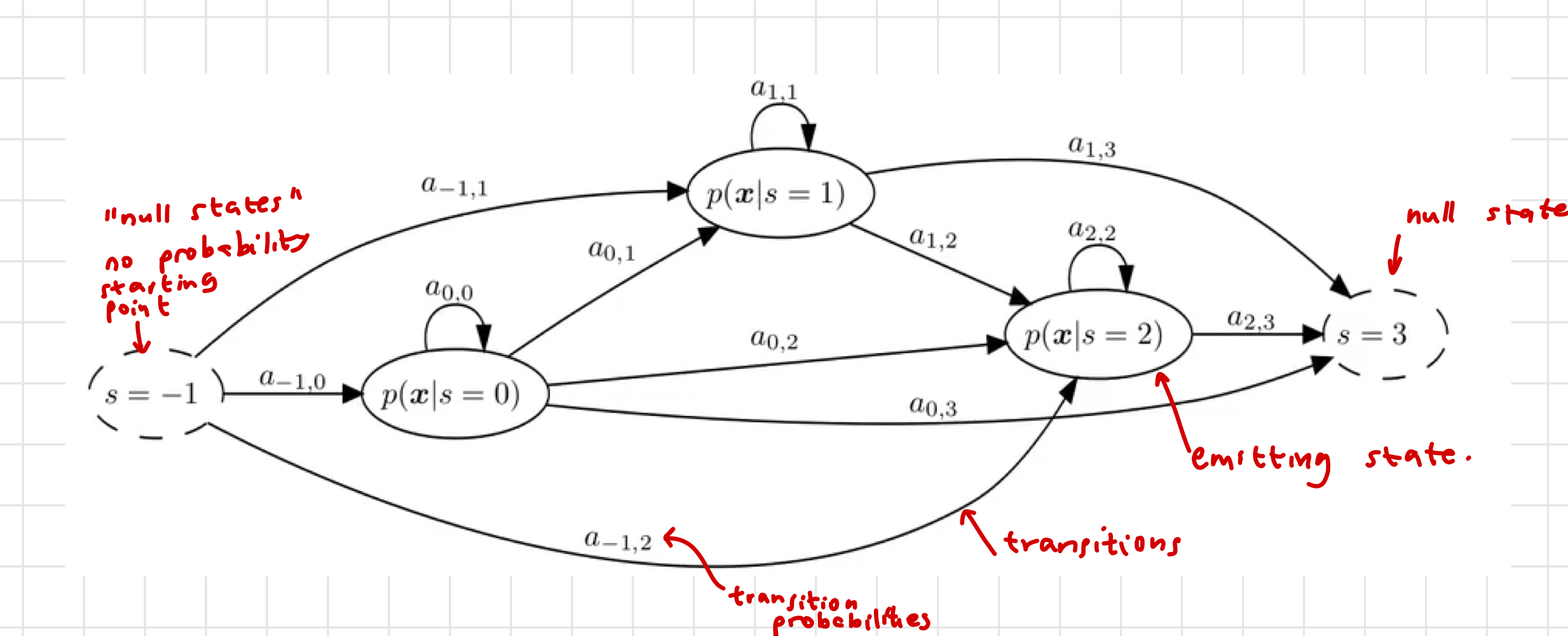
We do not know which state is active at any given time. This is why we refer to the model as a hidden Markov model, the states are hidden from us.
is the state at time (sample) . Since , the state at time zero can be any of the possible states. We add an known initialisation state (-1) and an end state (N). These states have no associated probability densities and are known as null states. The other states are called emitting states since they have associated densities which can be used to generate new feature vectors.
For this reason HMMs are generative models
Each emitting state behaves like a Naive Bayes system and has a distribution describing its feature vectors:
This gives the probability of the observation being generated by a specific state. With:
- being the time instant ()
- being the state number ()
Transitions between states are also probabilistic and modelled by the state transition matrix with:
Given the current state is , then is the probability that the next feature vector is generated by .
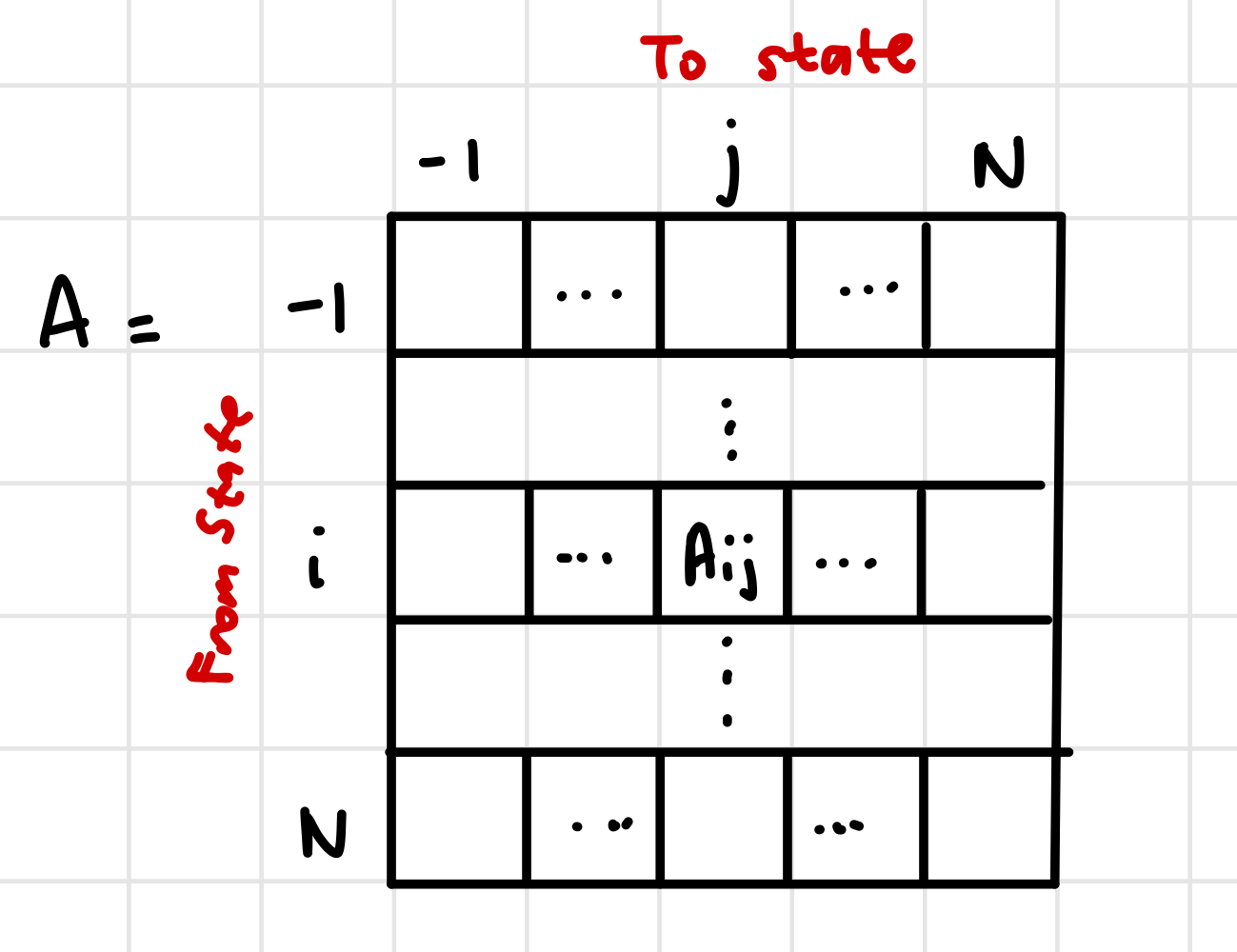
In Python, the transition matrix has a specific shape to reduce the memory used:
- The termination state N has no exiting states, and therefore may be omitted from the matrix to produce a N+1 row matrix.
- Since Python interprets negative indexes as counting backwards from the array, the -1 index is actually located at the Nth index.
- We can omit the -1 (last column) from the matrix since the initial state has no entering states.
This results in a N + 1 by N + 1 matrix, with rows and columns
Fundamental Assumptions
HMMs make two important assumptions about the relationship between the feature vectors:
1. Observation Independence
Given we know all the observations before the current feature vector and all states up till the current time, the likelihood of the -th feature vector is only dependant on the current state and is unaffected by both the previous states and feature vector sequence.
2. First Order Markov
The probability distribution of the current state, given both prior states and observations, is only dependant on the previous state.

HMM Topologies
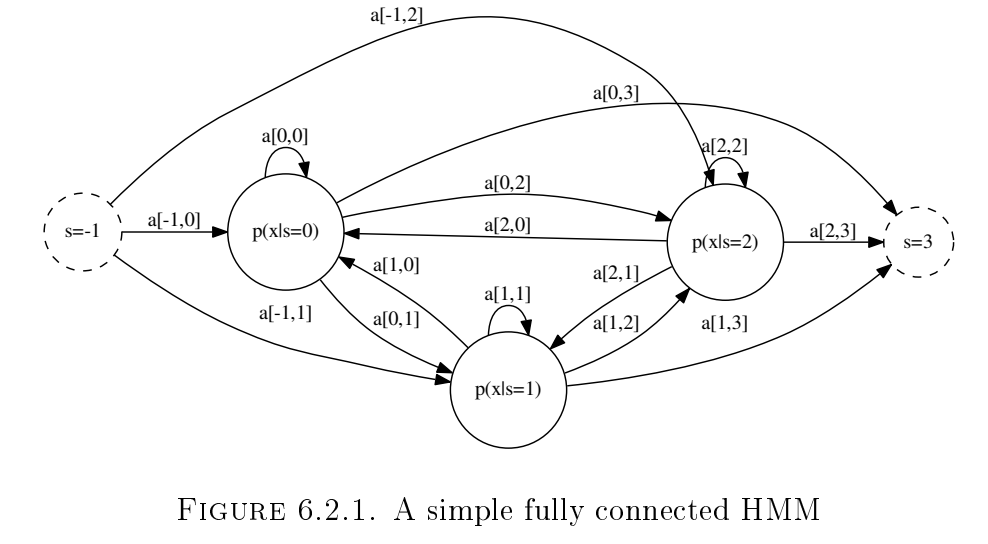
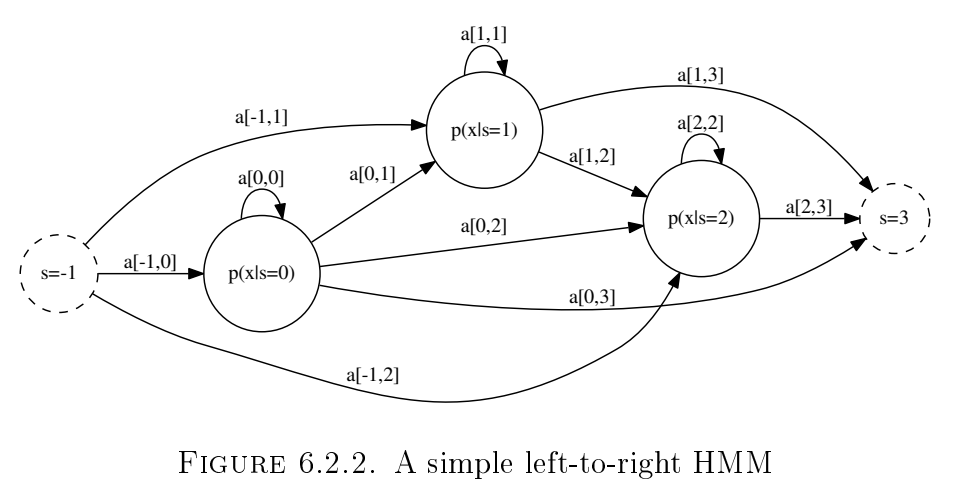
How does one choose the topology to use?
Bayesian techniques allow us to learn/infer the structure to choose the topology. We will not focus on that method in this course.
Instead, one can use prior knowledge to choose the topology:
- Left to right models are used when we have signals with a very definite time order which is non-repeating.
- Fully connected models are used for long repetitive sequence modelling.
Calculating the Likelihoods
We’d like to match a sequence of feature vectors to a model and get a likelihood score.
The likelihood of sequence being generated by model .
The Statistics
- Product Rule: or
- Sum Rule:
- Observation Independence:
- First Order Markov:
Direct Approach
We can solve the likelihood using marginalisation of all possible state sequence likelihoods:
Notice that the given is implicit (
We can solve for the joint probability as follows:
From this, we can see the last term is of the same form as the original probability, but one timestep shorter. Therefore we can solve for this likelihood recursively:
All these values are known or can be easily calculated. Thus, we have found a solution to the likelihood.
This approach in prohibitively complex to calculate due to the sum over all possible state sequences. The algorithm is complex as the possible state sequences grow exponentially with the length of the sequence.
This approach, however, does provide insights and fundamental understanding to how the sequences are calculated.
The highest scoring sequence is the optimal sequence
Forward Algorithm
We need an algorithm that can efficiently calculate the likelihoods in an efficient manner.
We define a new term, which we’ll called the forward likelihood:
Again, we want to find a recursive solution to this likelihood function:
Once again, the final term is the same as the original but one timestep less. We can recurse once more.
For the initialisation:
and
We then use the forward likelihood to calculate the total likelihood:
Final state is the terminating state .
This algorithm is in time complexity. Much more manageable.
We pack into a matrix.
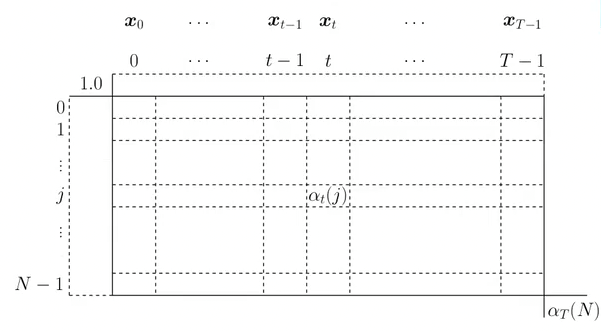
We fill it as follows:
- First column:
- Second column:
- Recursively fill columns:
- Final column:
Therefore the final algorithm is:
- Filling the matrix as above
- Computing the likelihoods:
Numerical Stability
During the recursive calculation, the numbers grow exceedingly small, resulting in underflow. To solve this we should use log scale.
We can still have underflow in the second term with the summation. To combat this we’ll use the log-sum exponent trick
Viterbi Algorithm: Most Likely State Sequence Calculation
TODO: show derivation to the simplification below
We’re essentially replacing the summation in the forward algorithm with maximisation.
We also keep track of the index which produced the maximum value, we call this the back pointer:
Numerical Stability
Unlike the forward algorithm, taking the log does not require the log-sum exponent trick:
Training
We’re to train the parameters of the HMM:
- Transition Matrix
- State distributions
For training we use training sequences. Training sequences need not be the same length.
M-Step
Suppose we know the state sequence associated with the training sequence of feature vectors. We could use the vectors beloning to each state to re-estimate the state distribution of all the states. Likewise, we can re-estimate the transition matrix by simply counting the number of transition and normalising it. See the equation below:
With being a count of the occurrences in the argument.
Unfortunately, we do not know which feature vectors in the sequence map to which state, as per the underlying assumption of HMMs. However, estimating the HMM parameters, we can use the Viterbi algorithm to estimate the optimal state sequence for each observation, which can be used instead of the true sequences. Using expectation maximisation we can iteratively improve our estimate of the model parameters.
EM Algorithm: Viterbi Re-estimation
- Initialisation: Get an initial HMM parameter set
- Assign sensible state sequences to the training sequences
- For a left-to-right model, one would typically subdivide the sequence into equal subsequences and assign each to the next state.
- For fully-connected model, one might use clustering (GMM), this will provide both states for each observation and the state distributions.
- Use the initial sequences to generate an initial model using the M-step
- Assign sensible state sequences to the training sequences
- EM Re-estimation:
- Expectation: Determine the optimal state sequence for each training sequence, and calculate the log likelihood - with being the viterbi estimated state sequence. Accumulate these ‘scores’ to test for convergence later:
- Maximisation: Perform the M-Step above to update the HMM parameters.
- Termination: Compare the current and prior total score . If it is in acceptable tolerance, terminate. Otherwise, repeat the EM Re-estimation step.
EM Algorithm: Baum Welch Re-estimation
The Viterbi Re-estimation method segments feature vectors into the particular state associated with each vector, it is a hard allocation (like KMeans).
Baum Welch’s Re-estimation performs soft allocation to each state (similar to how GMM assigns responsibility)
XXX: I’m not writing LaTeX for these formulas, so just go check the course notes
XXX: Let’s assume this section is not that important